Hello, my friends. My name is Bohdan. This is my True SEO school and here goes lesson number four: what data does a SEO use?
Before jump into this one, let’s quickly recall what we’ve been talking about in the lessons 1-3, because these were the lessons that introduced several important concepts, like the concept of customer utility, and also the concept of pipeline of data acquisition.
Recap of lessons 1-3
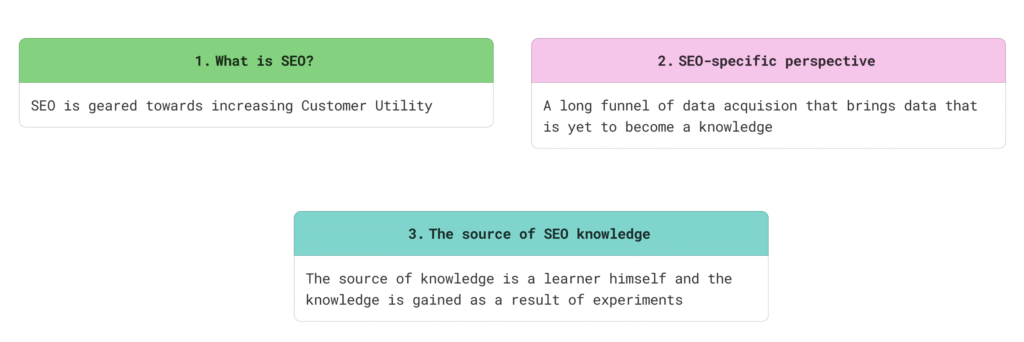
So, the first three lessons were mostly philosophical ones, and we discussed that SEO optimization is geared or directed towards increasing the customer utility. The concept of customer utility is central to understanding SEO because without it we can’t increase the number of clicks or conversions.
- We actually work to increase the customer utility and it’s through the prism of customer utility that we must understand all the rewards and all the effects of our work. SEO optimization is geared or directed towards increasing the customer utility.
- The SEO-specific perspective includes understanding that a SEO works with a very long pipeline or funnel of data acquisition, which includes lots of data, technical and user related, and to make use of these data, it’s important that they can suggest internal alignment within the company.
- And finally, the source of knowledge in SEO is a learner himself. This is to say, the experiment or a scientific activity is central to acquisition of knowledge. A knowledge must also pass the threefold test of being practical, coherent and just.
Now we are approaching the fourth lesson here. And this one, as well as other nearest lessons, are built around the concept of SEO funnel.
A concept of the SEO data funnel
So, SEO, as an activity, uses a funnel of data acquisition, which is not only long, but also successive, so the data acquired successively, not simultaneously. It all:
- starts with bots that access the page and, and
- ends up with a user that clicks somewhere on a button or a conversion button.
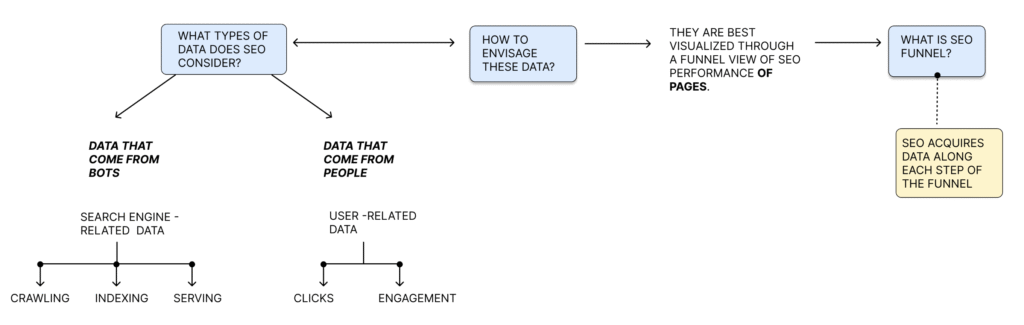
So without a doubt, you cannot omit one stage in order to progress to another one. So all the data acquired successively, step by step.
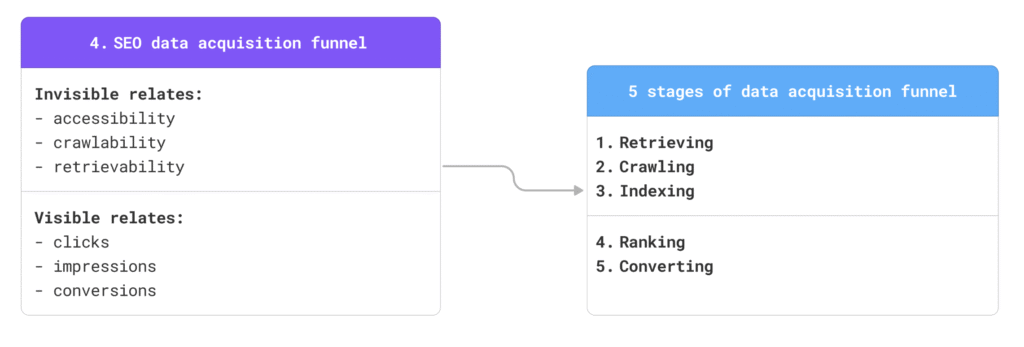
When we say a long funnel of data acquisition, we must understand that we are not talking about the mass of data that we acquire, but also that this funnel contains two parts: invisible and visible.
Invisible and visible parts of the data acquisition funnel
So invisible parts of data acquisition is something that is beyond the sight of a mere user, this is the part of the funnel that deals with the activity of bots and deals with crawling and indexing-related metrics, whereas a visible part deals with the way the page served in a search engine and gets metrics related to engagement with humans:
- clicks,
- impressions, and
- conversions.
So let’s get into more details about the structure of this funnel, how it works, what type of data we get along on each stage. The first important notion is that this funnel is pivoted to URL. So every type of data is attributed to your URL. This is for a good reason because when this data acquisition funnel starts, we start with bots accessing URLs. Without the ability to access a URL no data collection starts. So, a URL is an entry point to the funnel, and this is why all the data is attributed to URLs.
5 stages of data acquisition funnel
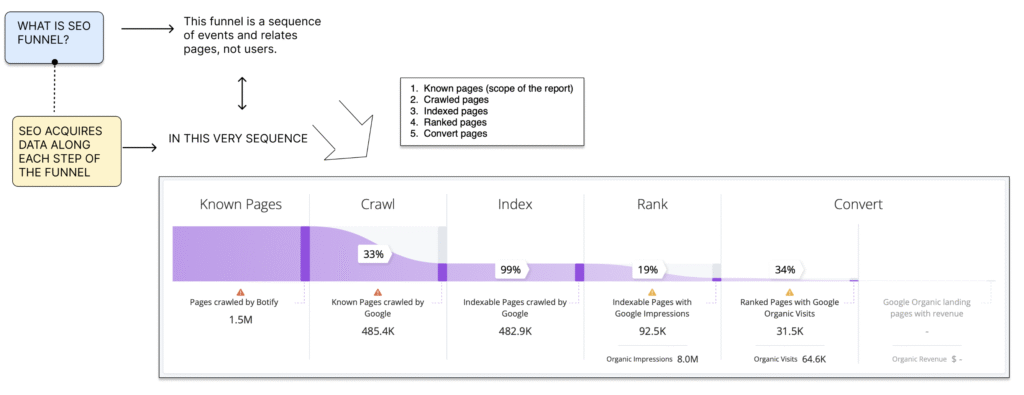
Apart from containing visible and invisible parts, this funnel might be divided in such parties as the number of:
- known pages, pages that physically exist,
- crawled pages, i.e. that has been accessed and crawled by bots
- indexed pages, i.e. that has been indexed and ended up in Google search results page, and finally,
- ranked pages, i.e. pages that were in the visibility zone, as well as
- conversions.
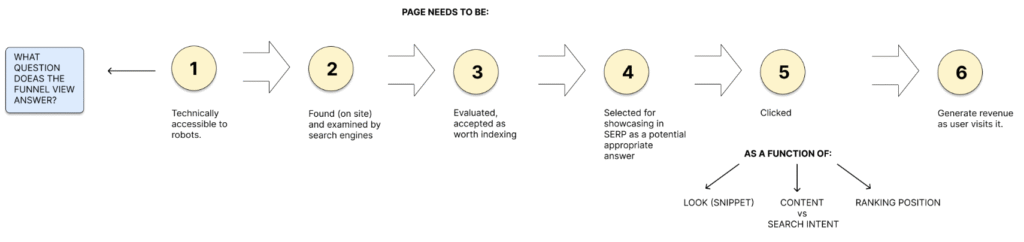
So as discussed in the funnel is a sequence of events which relates pages.The funnel view is quite instrumental to understanding the problem of where along the funnel, the opportunities are missed?
Crawling
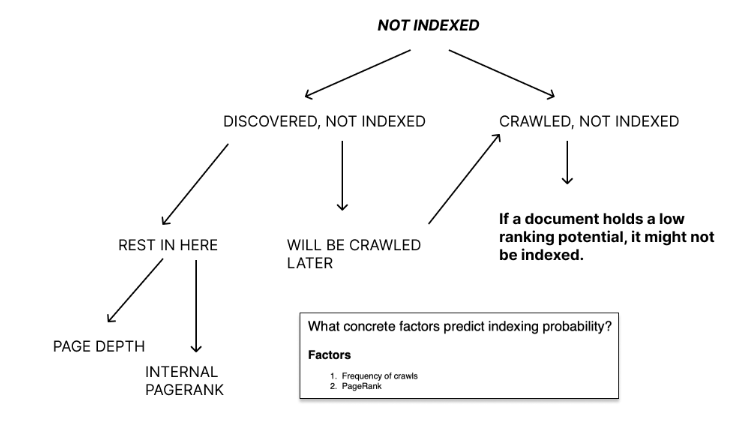
So, what is, what’s about the crawling stage? So the crawling stage deals with such data status codes, such as 200 (OK), 301 (permanent redirection) or 404 (Not found) etc. And also the very notion of crawlability such is Whether or not Page can be crawled by a by a search engine? This has a significance that whereas a page can be accessed by robots, it potentially can be indexed or included in index.
Indexing
Apart from crawling, there is an indexing stage where physically accessible pages can be made available to users, which means the possibility of earning clicks from search. And, notably, the indexing stage is a stage where crawlers make a decision whether or not to index a specific page or the basis of a certain construct of a customer utility.
So, without a direct recourse to customers the bots make predictions – on the basis of reverse analysis of user activity or user engagement – whether or not a page can earn clicks. And this is how they decide whether or not they want to index it.

So, it can be pages that have such statuses as “Discovered, not indexed” or “Crawled, not indexed” in the Google Search Console. Some of them will end up being indexed late, some of them not. So for this stage of discussion, this construct of customer utility is something that describes the indexing stage.
Ranking and Conversion
So the final element, which crowns this data in the funnel, is a search term. Apart from being a distinct type of data, search term is also one of the reference points of clicks and impressions. So, a search term or search query is the type of data that requires interpreting. It must be interpreted in terms of its intent and motivations etc. It’s a complex metric that requires our actual input here.
Questions
Let’s also discuss several questions that are instrumental to this discussion.
Why exactly is a page URL a reference point of a data acquisition funnel?
We mentioned that this is where bots start the journey and actually where the data acquisition funnel actually starts from.
So if a page would not be a pivot in this data acquisition, what can be a pivot here? The user appears only on the latest stage of the journey. The search query is an attribute of a user and also belongs to the lead stage of digital journey. So a page is a very handy thing that can work as a reference point.
Besides, the page is very instrumental as a vehicle of content. Search query is a small element of the page. And always start from the page indexed. There cannot be any case where a page is not indexed and still it gets featured in the search result, it’s nonsense. So only a page that goes through this funnel, acquires the data successively, stage by stage. Likewise, it goes live and may get some new data.
Where lies a divide between the visible and invisible part of the funnel?
Another question here, what, where lies a divide between the invisible and visible part of the funnel? So actually bots activity may be called invisible because it’s mostly so for ordinary users, whereas pages served in a search engine can be actually seen by the users and we can acquire the user-related engagement metrics. So this is where a divide happens and pages can be called visible. It is in a moment where a page at least gets ranked. So the “visible” part of the funnel starts from the page ranking it in search results, no sooner than this.
How to interpret the SEO data?
And, finally, an interesting question is how to interpret SEO data. We have a special topic on interpretation of SEO data, but for the sake of this discussion, let’s say that data acquired in some of the tech, invisible parts of the funnel might not need interpretation.
For some of this Google and company may issue explicit requirements to fix the tech. Whereas for the content or the visible part of the funnel, we actually need interpreting.
Interpretation takes into account several things:
- the search query or the universe search queries.
- a page or a URL and, finally,
- the intent.
So, with what intent a user has actually taken this or that form of words and where on a page does he end up? So this is the type of interpretation that’s interesting or fruitful for SEO.
But deeper down inside we may end up finding that every kind of interpretation is rooted in the business model. Because to understand such queries, we must understand the business itself. To attribute them to a page we must know how it is possibly done because it could be done by search engine by mistake. To actually assess it we must understand the motivation or the life of the customers. So this shortly is something rooted in the business, the business model.
Summary
Let’s make a short conclusion of this lesson.
So SEO your data is produced over a long funnel of data acquisition. It is not only long but successive. So the data is acquired step by step.
The funnel has “visible” and “invisible” parts. The invisible part is related to the activity of bots and visible – to the activity of humans or customers. The bot related data acquisition concerns crawling and indexing. This is where bots communicate with servers, with the web pages, and this is where they can access or not pages, where they can “think” pages are worth indexing or not based on a construct of customer utility. So it’s purely abstract without necessity to probe with the customer himself. This type of data acquisition may be called technical.
The user related data is about ranking the data acquired in the process of ranking of URL and the conversion. This is to say getting the impressions, clicks. So the user related data needs interpreting in terms of understanding search intent, search query, the motivation and the actual value proposition of the business.
Postback from Lesson 20
As regards SEO, Value Stream is a collection of necessary steps required to deliver value. In general, it encompasses three main stages: consumption of value by search engines, transformation and shipping it to users and consumption of the value by users. For example, consumption of value by search engines involves the steps of publishing documents, accessing it by search bots, crawling, retrieving the content etc, which produces the artefacts in the form of data that are capable of analysing.
Leave a Reply